AI Technical Translation
When I wrote the previous post on Worse Is Better, I mentioned that I wanted to work through a systematic round of classic computer science and software architecture reading.
The problem is that most of those classics are in English. It is not that I cannot read them at all. I just read them slowly. Slow enough that before opening a paper, I first need half a day of psychological preparation.
So this time I wanted to try something: could I use Codex to build an agentic translation flow that turns an English paper into a Chinese Markdown file that is readable, editable, and easy to navigate?
I started with Butler Lampson’s Hints for Computer System Design. The goal was not “one-click translation.” The goal was to split the work into stages: PDF -> Markdown -> Chinese translation -> terminology cleanup -> cross-references -> verification.
The final Chinese version ended up here: Hints for Computer System Design.
Data
| Item | Number |
|---|---|
| Original PDF | 27 pages |
| Original Markdown | 556 lines, about 13,853 English words |
| Main body of the source | about 12,961 English words |
| References | 55 entries, about 892 English words |
| Chinese Markdown | 482 lines, main body about 18,632 Chinese characters |
| In-body citation links | 83 |
| Terminology candidate file | 333 lines |
| Terminology review report | 41 lines |
Judging by file timestamps, it took about 56 minutes from receiving the original PDF to generating the reviewed Chinese Markdown. From the first raw Markdown extraction to the final translation and terminology report, it took about 45 minutes. The whole process involved more than ten rounds back and forth between me and Codex. Of those, the major file-editing steps were roughly eight rounds, using about 600k GPT-5.5 tokens.
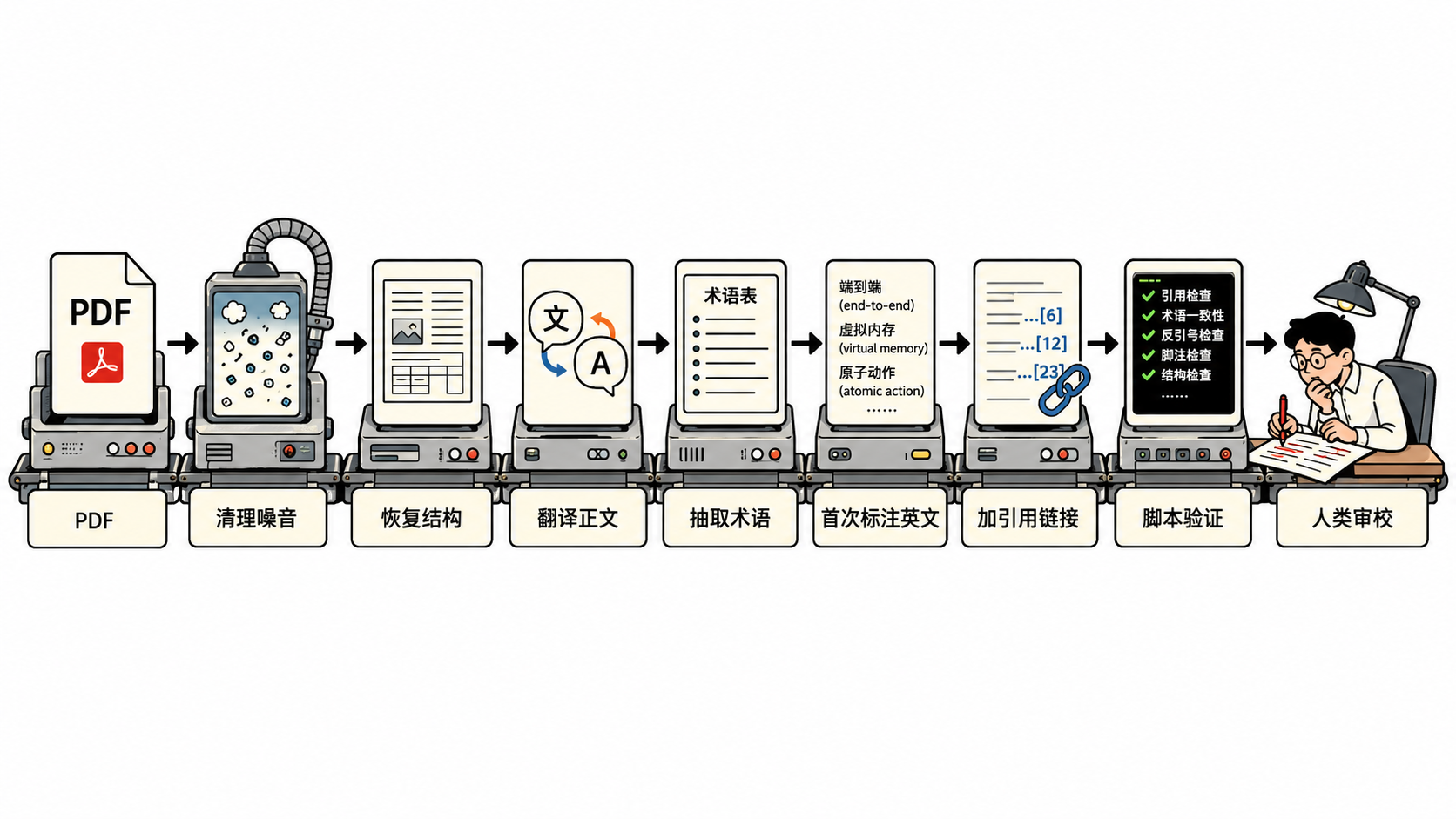
If this had gone to a human technical translator, the main body alone would have been about 13,000 English words. A translator familiar with computer systems might need a week for the first draft. Add PDF cleanup, diagram reconstruction, terminology normalization, citation repair, and full review, and two weeks would not be an aggressive estimate. If the translator were not already comfortable with systems papers, it would likely take longer.
Compared with that, this run with AI took less than an hour, and it was still the first time I was feeling out the workflow. Once the agentic translation flow is stable, the PDF extraction steps, terminology handling, citation repair, and verification scripts can all be reused, which should reduce the time further.
So the clearest conclusion from the experiment is not that AI is perfect. It is that the cost structure has changed. Work that used to be measured in weeks has been compressed into work measured in hours. But quality and responsibility did not disappear. They moved into workflow design, terminology judgment, and final review.
The original PDF was a text PDF, not a scan. But PDF stores the positions of text on a page, not the structure of an article.
So the first step was not translation. It was structure recovery.
I gave all of the programming work to Codex. After checking the local environment, it chose PyMuPDF for text extraction and produced the raw Markdown. Once the text came out, it still had headers, page numbers, broken lines, scrambled paragraphs, and a damaged Figure 1.
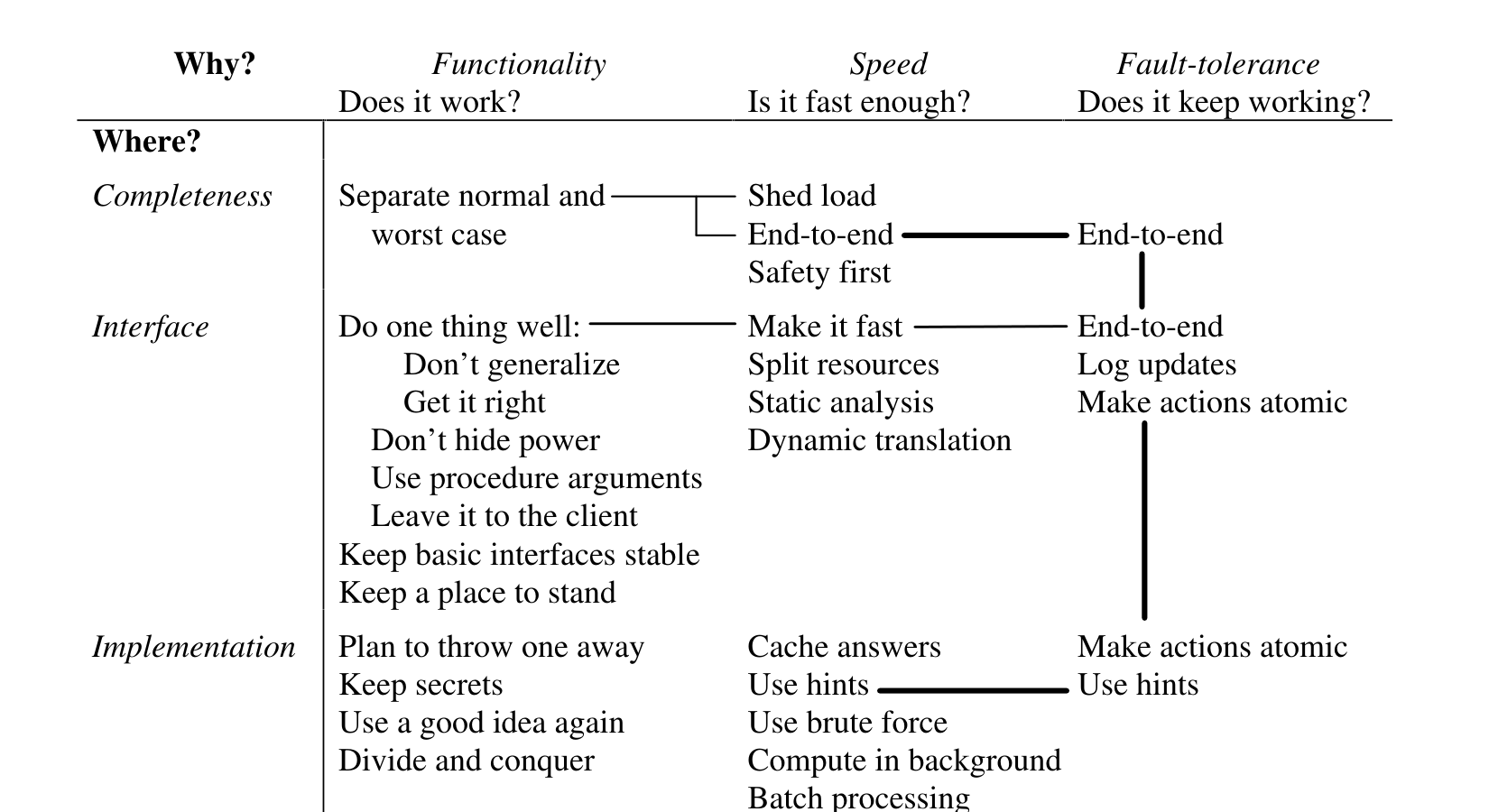
Figure 1 is the only figure in the whole essay, and it is basically a text table. Codex rebuilt it as a Markdown table and cleaned up the headers, page numbers, and paragraph breaks.
The lesson from this step is simple: do not rush into translation. Repair the input until it is worth translating. Otherwise AI just turns bad structure into a more fluent version of bad structure.
Translation and terminology
I gave the body text to Codex for translation, while keeping the references in English. The requirements were to preserve the Markdown structure, code snippets, proper nouns, and citation numbering.
The real problem was not “English becomes Chinese.” It was consistency.
Take hint as an example. In the title it can become something like “maxim” or “advice,” so the final Chinese title uses a word closer to “maxim.” But in the technical context of the body, it is closer to a system-level clue or cue given to the caller or implementation, so the technical rendering was normalized one way throughout.
Another example is make actions atomic, which ended up in a more direct Chinese phrasing equivalent to “make actions atomic” rather than a heavier noun phrase. shed load was also adjusted from a too-literal version toward a more idiomatic one.
To enforce consistency, I first had Codex extract terminology candidates. It produced 333 lines of candidates, then I manually removed the items that were too ordinary or not worth annotating in English.
What remained were terms that actually affect understanding, for example:
- functionality
- fault-tolerance
- end-to-end
- virtual memory
- atomic action
- hint
The tricky part here was not listing the terms. It was only preserving the English on first appearance and then using Chinese afterward.
If you skip that step, you usually end up in one of two bad extremes: either the whole page becomes Chinese (English) everywhere and reads like a bilingual annual report, or you preserve no English at all and force the reader to guess which original English term a translation corresponds to.
A human can do this too, but it is exhausting. One person has to remember, all the way through the translation, whether a term has appeared before. That is basically like acting as a budget compiler while translating and somehow not crashing.
The final rule became: if a term is genuinely technical, potentially ambiguous, and the original English is worth preserving, annotate it on first appearance. Everywhere else, keep only the Chinese.
Citations
The source has a large references section. Markdown supports in-file anchors, so the [6] references in the body could be turned into [6](#ref-6), while the corresponding entries in the references section got <a id="ref-6"></a>.
I also turned the references section into a real continuous numbered list instead of leaving blank lines between each entry.
There was one footnote pass too. The draft originally had a [^1]. At first I considered rewriting it as [0], but it looked ugly after the title. In the end I moved the publication note back into the body and removed that cross-reference entirely.
Citation handling is tedious, but important. It determines whether readers can jump from the body into the references, instead of staring at a pile of numbers they cannot click.
This sounds annoying, but in practice it took about two prompt rounds. If I had done dozens of citations and 55 reference entries by hand, it would have taken at least half a day, and after that most people’s eyes are no longer fit for precision labor.
Verification
Long-form translation cannot rely on eyeballing alone.
I had Codex work with scripts to check several categories of issue:
- whether references were accidentally translated
- whether backticks were balanced
- whether every citation link had a matching anchor
- whether there were still unlinked citations
- whether anything like
[^1]or#ref-0remained - whether the terminology report still had candidate terms where the Chinese appeared but the English did not
Human review also found several problems that both the model and the PDF extraction could easily miss.
For example, superscripts had been lost during extraction, so 128 n/2 had to become 128^n / 2, and O(n 2.5) had to become O(n^2.5). Codex even caught correctness issues in translated code and mathematical expressions. Other choices, like how to render hint or whether to keep the [0] citation, still needed human judgment.
So the core of this flow is not “let AI translate.” It is putting AI inside a process that can be checked.
That is very similar to agentic coding. In older workflows, coding was the most time-consuming part. Now code generation is often fast, and the harder part is verification. Agentic translation is the same: the translation itself is often quick, while the slow part is restoring PDF structure, enforcing terminology consistency, repairing references, and making sure a sentence was not quietly mistranslated.
Translation is going to get repriced
This experiment does not prove that AI can translate perfectly. It does show that a lot of translation work is going to be repriced, especially technical documents, internal materials, first-pass paper translations, subtitles, manuals, and customer-support knowledge bases.
Right now, even a very low rate like 60 RMB per 1,000 English words still exists in the market. For a body text of about 13,000 English words like this paper, a human translation quote would usually land somewhere in the several-hundred to low-thousand RMB range. Codex can push the model-side cost down to only a few RMB. Even after you include human review time, the price anchor has already shifted.

The old flow was human beings translating slowly. The new flow is more likely to be: AI drafts the translation, AI normalizes the terminology, AI repairs the formatting, AI runs the checks, and the human spot-checks, fixes key areas, and takes responsibility.
Translation will not disappear. But the value of “move English into Chinese sentence by sentence” is going to drop sharply. Translators will look more like reviewers, editors, domain consultants, and the final sign-off owner.
And this does not stop at translation. Draft writing, document organization, junior research-assistant work, report polishing, and low-level code movement will all face similar pressure.
AI does not need to replace an entire profession. It only needs to eat the most stable, repetitive, and easiest-to-price part of the work. Once that happens, the rest of the role gets repriced.
For me, AI cannot replace my understanding of Lampson’s paper. But it can turn a raw PDF into a Chinese Markdown file that is readable, navigable, and terminology-consistent.
That is roughly the outcome I wanted: not for AI to read the classics for me, but for it to clear away the mechanical, repetitive, time-consuming work that stands in front of reading.
One side note: this blog post was also written by AI after it read through the Codex translation session:
AI helped me translate the paper, AI helped me organize the process, and then AI helped me write a post explaining how AI helped me translate the paper.
Tags: AI, Codex, Translation, Markdown, Classic Reread